My Research
I’ve had an interesting journey over my Ph.D. career. My work started with Josiah Hester at the Ka Moamoa lab, designing an energy-harvesting platform for data-gathering. Later, I moved to working with Seda Ogrenci and Fermilab, optimizing and implementing an algorithm for interpreting the output of a quantum computer. I plan to merge these two approaches, spending the rest of my Ph.D. program exploring the relatively-unknown space of ultra-low-power hardware-accelerated TinyML.
Key Research Interests
Hardware acceleration, embedded systems and sensor platforms, edge and on-device TinyML acceleration, ultra-low-power systems, energy harvesting, distributed computing, designing for sustainability and resilience.
Projects
Vibrance Project
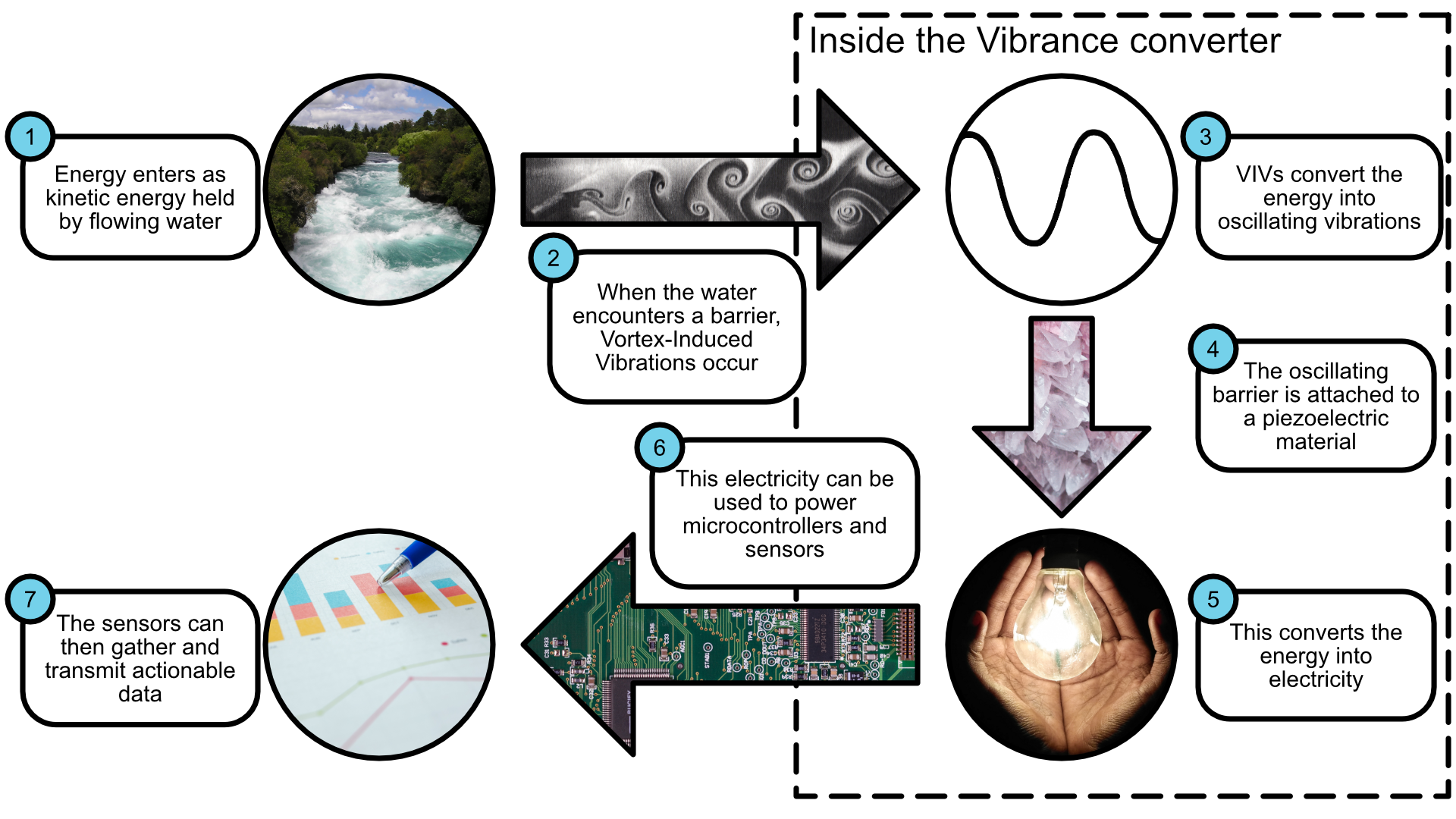
Vibrance was a research project I undertook in the early part of my Ph.D. career with the Ka Moamoa lab. The goal was to create a batteryless sensing platform for use in remote flowing-water research and monitoring. The energy-harvesting system was to operate on the principles of vortex shedding and vortex-induced vibrations,1 generating sufficient energy from the flow of water to power sensors for real-time monitoring of water pollutants. Additional plans for the project proposed the use of a piezoelectric Underwater Acoustic Communication (UAC) network between sensor nodes similar to the one proposed by Steinmetz and Renner,2 such that data could be transmitted and centralized in a single, higher-power node with the ability to transmit data back to researchers using LTE-M or a similar technology.
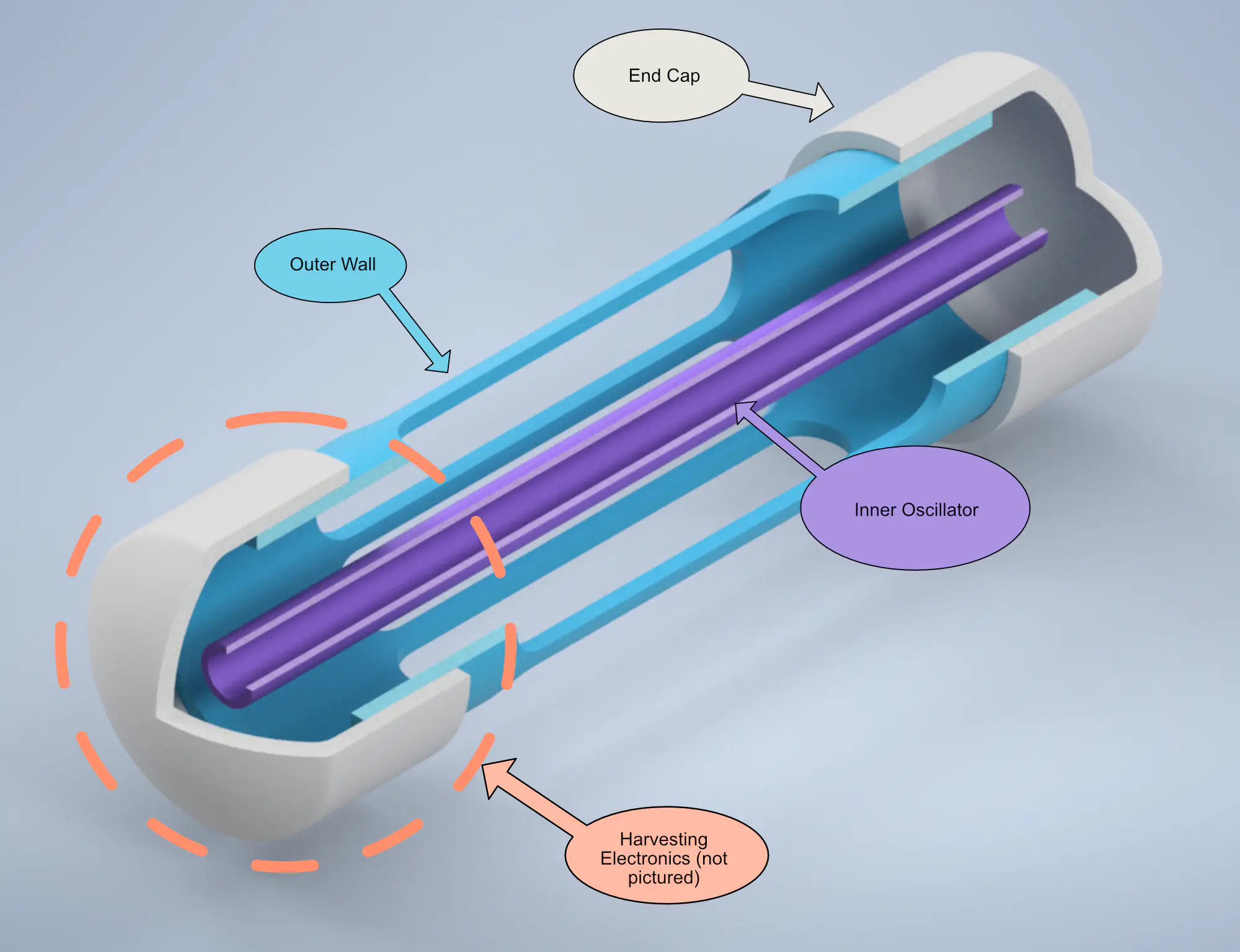 Work for the project took place primarily in 2022. I performed fluid simulations and used Autodesk Inventor to design a prototype energy-harvester. Part of the project’s goals was to build at a minimal cost, and as such, the energy harvester was designed using easily-available PVC pipe. Some of the biggest challenges I ran into at this phase included waterproofing and managing fouling in difficult underwater environments.
Work for the project took place primarily in 2022. I performed fluid simulations and used Autodesk Inventor to design a prototype energy-harvester. Part of the project’s goals was to build at a minimal cost, and as such, the energy harvester was designed using easily-available PVC pipe. Some of the biggest challenges I ran into at this phase included waterproofing and managing fouling in difficult underwater environments.
Unfortunately, in 2023, Josiah and the Ka Moamoa lab moved from Northwestern University to Georgia Tech. I was unable to move with the lab for personal reasons, and as such, I had to suspend the project and switch the direction of my research. I hope to resume work in this direction in the future, as I still believe the concept holds a great deal of promise!
HERQULES Hardware Implementation
One of the biggest problems of the Noisy Intermediate-Scale Quantum (NISQ) era is noise. The control hardware that initializes the quantum state, spontaneous relaxation and excitation events during the calculation process, and the readout hardware that interprets the final quantum state can all introduce errors that lead to an incorrect final output.
Of particular note is the readout process - that is, the process of measuring the state of a quantum computer after a quantum algorithm has been run and interpreting each qubit as a binary value. As the number of qubits in a quantum computing system increases, it becomes increasingly important to be able to read out multiple qubits simultaneously, in order to decrease the hardware requirements while maintaining a fast enough readout cycle to minimize spontaneous relaxation events. However, simultaneous multi-qubit readout introduces its own problems. Frequency-multiplexed readout, where each qubit is induced to resonate at a different frequency in response to an interrogation pulse, can lead to cross-talk between qubits, where qubits at nearby frequencies can affect each other, leading to incorrect readout results.
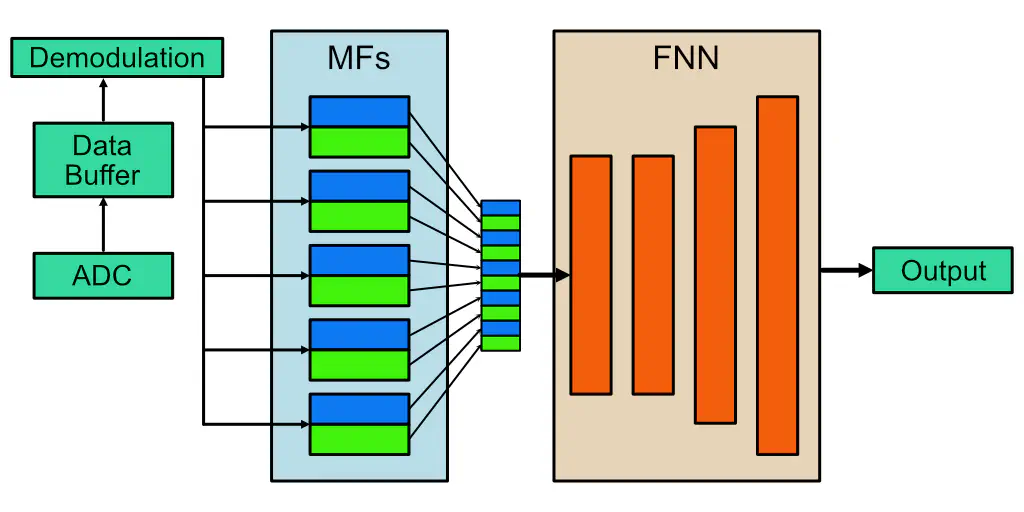 In 2022, Maurya et al. released a model called HERQULES,3 which aimed to help increase the accuracy of frequency-multiplexed readout systems using a hybrid machine-learning approach. FNNs excel at learning to account for cross-talk; however, a full-size FNN running on the entire system input is much too large to fit in a standard FPGA. Thus, HERQULES uses a set of matched filters for dimensionality reduction, training an FNN on the output of those filters. This system was shown to function much better than matched filters alone for a 5-qubit multiplexed readout system, and initial results indicated that it would be feasible to implement in hardware.
In 2022, Maurya et al. released a model called HERQULES,3 which aimed to help increase the accuracy of frequency-multiplexed readout systems using a hybrid machine-learning approach. FNNs excel at learning to account for cross-talk; however, a full-size FNN running on the entire system input is much too large to fit in a standard FPGA. Thus, HERQULES uses a set of matched filters for dimensionality reduction, training an FNN on the output of those filters. This system was shown to function much better than matched filters alone for a 5-qubit multiplexed readout system, and initial results indicated that it would be feasible to implement in hardware.
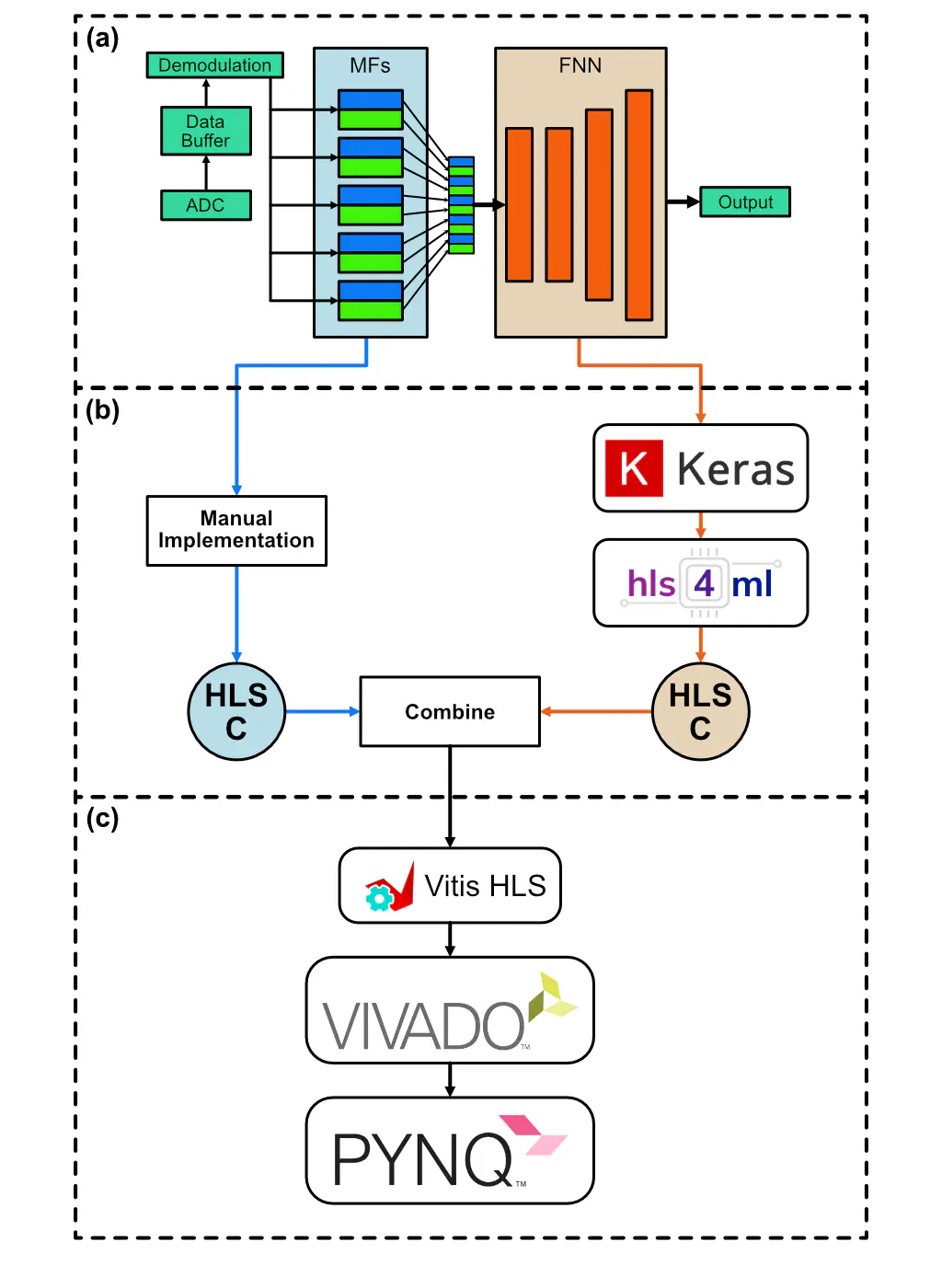 My contribution to this effort was to optimize this system to run on physical FPGA hardware, in a continuation project performed in collaboration with Fermilab. In exploring potential designs for the system, I identified one candidate design optimized for minimal resource consumption (and thus maximum scalability) and another optimized for accuracy. These models were run on a physical FPGA (the Xilinx ZCU216, specifically), with only minimal performance losses compared to the original software implementation.
My contribution to this effort was to optimize this system to run on physical FPGA hardware, in a continuation project performed in collaboration with Fermilab. In exploring potential designs for the system, I identified one candidate design optimized for minimal resource consumption (and thus maximum scalability) and another optimized for accuracy. These models were run on a physical FPGA (the Xilinx ZCU216, specifically), with only minimal performance losses compared to the original software implementation.
Presentations
“Resource Efficient Multi-Qubit Readout on FPGAs” at the APS Global Physics Summit, March 18, 2025.
Current Status
We are in the final stages of preparing a paper for this work. We hope to publish by the end of the year.
ExSeOS Hardware DSE Framework
In performing Design-Space Exploration experiments for the HERQULES implementation, it became apparent that the ’traditional’ workflow - using Jupyter Notebooks and manually setting parameters - required far more manual intervention and was far less scalable than ideal.
The process of DSE is well-suited to parallelization. Since large portions of the experiment are repeated, it is a relatively simple process to distribute each run across a different node, gathering data points in parallel and optimizing via an automated process. The ExSeOS project aims to create a framework for running workflows similar to that used to optimize HERQULES, allowing future work to be performed more quickly and with far less need for manual intervention.
Presentations
“Accelerating Reproducible FPGA Machine Learning Research with a Workflow Management Framework” at the FastML for Science conference, October 17, 2024.
Current Status
In 2024, the initial stages of the project were completed, including the fundamental framework for encapsulating workflow steps and running optimization experiments with them. This work was presented at FastML for Science in 2024.
In the next few months, I plan to implement the parallelization element of the work, creating a tool capable of automatically running DSE experiments in parallel. Once completed, the tool will be released open-source and details on the framework itself will be published.
Planned: Field Multi-Tool Platform
Once my work on HERQULES and ExSeOS is completed, my plan for the remainder of my thesis is to investigate the possibility of miniaturization for FPGA-based machine learning accelerators. The eventual goal of this work is to create a low-power platform suitable for deployment in the field, taking and classifying readings automatically using specialized networks developed for a small embedded FPGA. This tool would be of great use to researchers engaged in fieldwork - for example, environmental scientists and ecologists.
The planned end date for this is June 2026; however, due to the scope of the project, there will be a great deal of opportunity to further enhance the work after that.
Footnotes and References
-
H. D. Akaydın, N. Elvin, and Y. Andreopoulos, “Wake of a cylinder: a paradigm for energy harvesting with piezoelectric materials,” Experiments in Fluids, vol. 49, no. 1, pp. 291–304, July 2010, doi: 10.1007/s00348-010-0871-7. ↩︎
-
F. Steinmetz and B.-C. Renner, “Taking LoRa for a Dive: CSS for Low-Power Acoustic Underwater Communication,” in 2022 Sixth Underwater Communications and Networking Conference (UComms), Aug. 2022, pp. 1–5. doi: 10.1109/UComms56954.2022.9905674. ↩︎
-
S. Maurya, C. N. Mude, W. D. Oliver, B. Lienhard, and S. Tannu, “Hardware Efficient Neural Network Assisted Qubit Readout,” Dec. 07, 2022, arXiv: arXiv:2212.03895. doi: 10.48550/arXiv.2212.03895. ↩︎